필자는 통계학에서는 미국에서 스탠퍼드 다음에 보내UC버클리대에서 통계학 학사를 취득하고 머신 러닝에서 가장 유명한 카네기 멜론에서 통계학 석사를 취득했다.그래서 사실은 전공은 모두 통계였다.그래서 학교 다닐 때 R에서 프로그래밍을 주로 하고 머신 러닝 수업도 많이 받았지만 통계 모델 수업도 많이 받았다.지금은 데이터 과학자로 일하고 있고 주로 개발 모델은 xgboost 같은 유명한 머신 러닝 모델이다.오늘은 블로그에 통계 모델과 기계 러닝의 가운데 왜 실무에서는 주로 기계 학습 모델이 사용되느냐는 질문을 받았다.자세히 파고들어 가면 더 많은 이유가 있겠지만 쉽게 풀어 봤다.**내가 대학과 대학원을 전부 미국에서 나온 관계로… 그렇긴이 기사의 대부분은 영어로 사용될 것**뎃사에서 항상 통계학의 세부 분야보다는 ML이 강조되고 있지만 통계학의 세부 분야(survival analysis, generalized linear model또는 regression discontinuity)은 실무에서 많이 쓰이지 않는 편인가요?ML이 왜 사업권에서 주류가 되었나 이런 기술적인 것이 궁금하네요.예측력에 대한 performance이 되니까요?
필자가 느낀 통계측 모델과 머신러닝 모델의 가장 큰 차이-예측을 함에 있어 interms of predicting

통계학은 이전 데이터를 입수하기 어려웠을 때 발전한 학문이다.한 population에 대해서 알고 싶지만, 그 전체 인구의 데이터가 얻을 수 없기 때문에 샘플링을 기본으로 한다.그래서 이 샘플이 전체를 대표한다는 가정 하에서 만들어진 이론이 많다.다시 말하면 내가 전체 데이터를 볼 수 없으므로 이 작은 샘플을 가지고 있는 모델로 만든다.그리고 저의 가정이 옳다는 전체 아래 이 모델에서 나온 결과를 전체로 확장할 수 있다.다시 말하면 이들의 가정이 맞지 않으면 통계 모델 자체를 쓰지 못하지 않나!!!물론 그래서 non parametric test로 바꿀 수도 있지만 전체적으로 보면 통계학이라는 학문은 전체 데이터가 없을 때 불가피하게”나의 데이터는 이러한 분포에 따를 것”이라는 가정 하에서 만들어진 이론인 경우가 많다.반면, 머신-러닝은 빅 데이터와 함께 떠오른 학문이다.그래서 데이터가 많으므로, 이 데이터를 이용하고 예측을 한다.사람의 배우는 방법과 매우 흡사하다.아기가 처음에 걸음 걸이를 배울 때, 다리의 각도나 동력을 계산하고(이전의 과학이 이처럼 한 공식 이론을 통해서 결과를 이뤘다)걸음 걸이를 배우지 않는다.이것 저것 걸고 넘어져서 보거나 하면,”아, 이렇게 하면 걷어”과 자연스럽게 배우게 되는 것이다.여기에 가정 따위는 필요 없다필요한 것은 100회 1000회로 걸음을 하고 볼 일이다.마찬가지로 대부분의 머신 러닝 모델은 assumptions를 별로 없고 데이터를 주는 대로 배운다.통계 모델과 기계 학습 모델은 기본적으로 목적이 다른<-꿈자리 씨가 코멘트로 정정하시고 내용을 추가
인기글

 보장구 모델소개")

통계 모델은 가정을 통해 단순 표본(sample)이 아닌 모집단(population) 특성을 설명할 수 있다는 장점이 있다. 그래서 예측(prediction)이 아니라 추론(inference)이 중요하다면 통계 모델을 사용한다. VS. 머신러닝 모델은 인과추론보다는 단순히 예측만 잘하면 될 때 주로 사용한다. 질문을 듣자마자 떠오른 대답

1) 머신러닝 모델이 대부분의 통계 모델보다 예측을 잘한다2) 통계 모델은 가정해야 할 것이 많기 때문에 실제 데이터로 그러한 조건을 맞추기 어렵다3) survival analysis는 제가 하는 분야가 아니라 모르는 1. 머신러닝 모델이 대부분의 통계 모델보다 예측을 잘한다 머신러닝 모델이 성능이 좋다는 예는 인터넷에 많습니다.

보험계는 아직 주로 GLM을 사용하고 있는데 아마 이렇게 머신러닝이 잘 작동한다는 것이 입증되면 언젠가 달라지지 않을까 싶다.

보험 측 프로젝트를 GLM과 ML 모델을 사용하여 비교한 결과 머신러닝 기반 모델이 predictability가 높은 것을 확인할 수 있다.

현대 머신러닝은 스파이크 AriS 예측에서 GLM을 훨씬 능가합니다. 벤자민 1세 휴고 L. 페르난데스2, 터커 톰린슨

2. 통계 모델은 가정해야 할 것이 많지만 머신러닝 모델은 가정이 거의 없는 Assumptions!

GLM(가정)좀 은 많만 를 선형 관계 가정 GLM은 변환된 기대 응답과 링크 함수와 설명 변수 사이의 선형 관계를 가정합니다.예를 들면, 바이너리 로지스틱 회귀 로짓트(σ)=β 0+β 1x가에게보내는 답을 feature.d.linearations.linearship.lineeration을 참조하세요.독립 가정(independent assumptiony).내가 만드는모델이 고객마다 예측을하는 거면상관 없지만, 만약에오더(order)마다예측을 하는거면 같은고객이 여러오더 데이터를가지고 있을수 있으므로이 가정도만족하기 어렵다반면에 머신러닝모델을 쓸거면 이런가정을 생각할필요가 없다 3.Survival Analysis는내가 하는분야가 아니라왜 머신러닝이더 잘 쓰이는지 찾아봤다
GLM(가정) 좀 은 많 만을 선형 관계 가정 GLM은 변환된 기대 응답과 링크 함수와 설명 변수 사이의 선형 관계를 가정합니다.예를 들어, 이진 로지스틱 회귀 로짓(β)=β0+β1x가에 게 보는 답을 feature.d.linearations.linearship.lineeration을 참조하세요. 독립 가정(independent assumptiony). 내가 만드는 모델이 고객 마다 예측을 하는 거면 상관 없지만, 만약에 오더(order)마다 예측을 하는 거면 같은 고객이 여러 오더 데이터를 가지고 있을 수 있으므로 이 가정도 만족하기 어렵다 반면에 머신러닝 모델을 쓸 거면 이런 가정을 생각할 필요가 없다 3。 Survival Analysis는 내가 하는 분야가 아니라 왜 머신러닝이 더 잘 쓰이는 지 찾아봤다

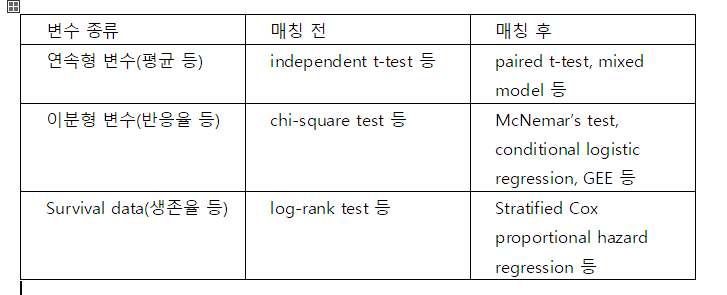
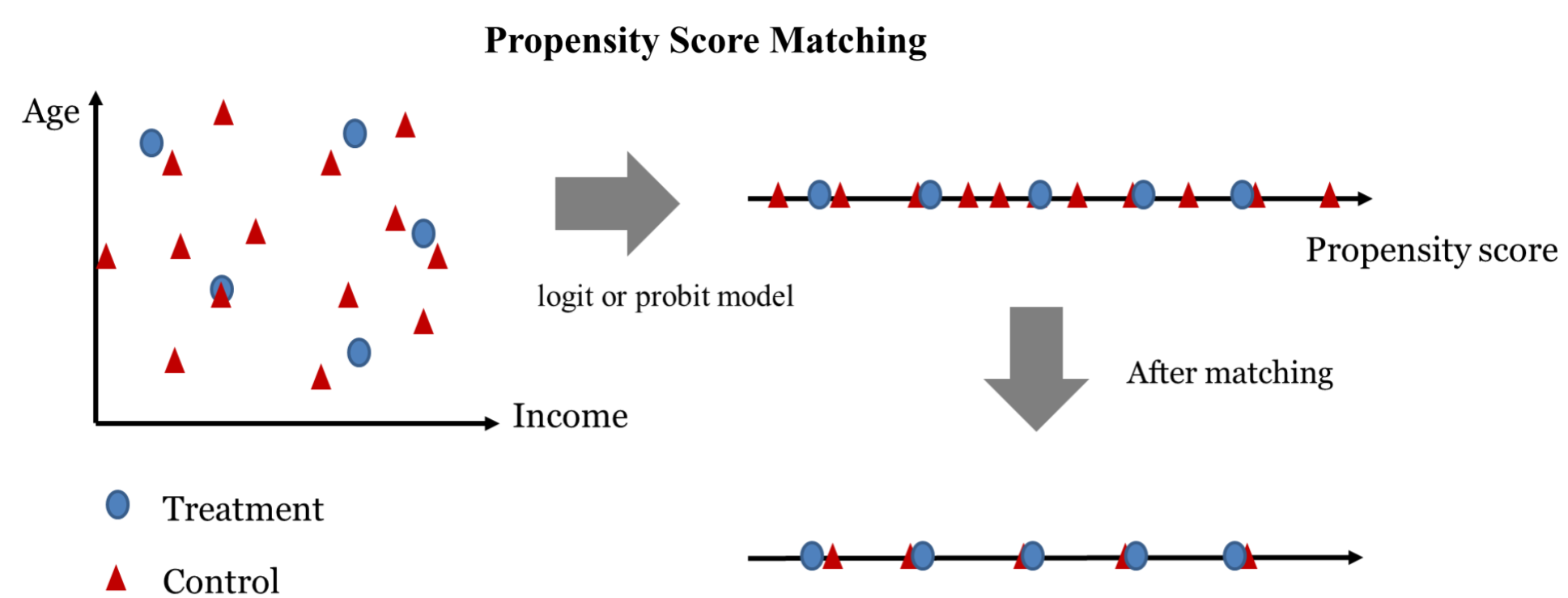
https://www.imperial.ac.uk/media/imperial-college/faculty-of-engineering/computing/public/1718-ug-projects/Jingya-Wang-Applying-machine-learning-approaches-to-survival-data.pdf 덧붙이자면統計モデルは統計学なりの長所があり(小さなデータでも結果を導き出すことができるとか/単純予測にとどまらず変数間の関係を推論できるとか)、まだデータサイズが小さい分野では統計モデルが多く使われている。 最近、会社でpropensity score matchingをしなければならず、関連マシンラーニングモデルがなかったので、Rを利用して伝統的な統計的方法でcontrol groupとtest groupをmatchした。 このように統計学は統計学なりの使い道がある。 しかし、上で見た通りデータが多く、同じことをやり遂げるマシンラーニングモデルがあり、推論は必要なく単純に予測だけが重要な場合、統計モデルとマシンラーニングモデルを回してみた時、マシンラーニングモデルの方が性能が良いということが立証され、マシンラーニングがより活発に使われ始めたのではないかと推測してみる。 私は個人的に統計学を専攻したが、マシンラーニング授業がもっと好きで、そして仕事もずっとマシンラーニングモデルを使うので、こちらの方が楽だ。 ** この文は私のとても短いグーグルリングと私の考えを土台に書かれた文なので一般化することは難しいかも知れない **