만반 잘~~ 반갑습니다.잘 부탁드립니다。현재 Bb7942는 다양한 OTT서비스 중 유일하게 넷플릭스 하나만 구독하고 사용하고 있습니다.여러가지 OTT서비스가 존재하지만 언론 노출을 줄이기 위해서 최소화의 일환으로 하나만 이용하고있습니다만, 최근 둘째 딸과 드라마를 보게 열중하고 나름의 넷플릭스 사용 시간이 늘어나고, 문득 넷플릭스가 유저에게 어떤 방법으로 미디어를 노출하고 추천하는지가 궁금해서 찾아봤는데 원문을 해석하고 정리하면서도 솔직히 어렵네요.그래서 언론은 생각 없이 즐기는 것이 옳다고 생각합니다.그러나 준비해서 혹시 신경 쓰이시는 분이 계실까라고 생각하고”넷플릭스 추천 시스템의 심층적 분석”이란 제목으로 게시하고 보겠습니다.Deep Dive into Netflix’s Recommender System넷플릭스가 어떻게 퍼스널 라이즈를 통해서 80%스트리밍 시간을 달성했는지에 대해서 설명합니다.

sunder_2k25, 처 스플래시를 해제하다

넷플릭스는 영화나 텔레비전 쇼의 스트리밍 서비스이며 오늘날에는 대부분의 사람에게 동의어입니다.그러나 대부분의 사람이 모르는 것은 넷플릭스가 1990년대 후반에 구독 기반 모델로 출발했다가 미국의 민가에 DVD를 게시했다는 것입니다.넷플릭스상(The Netflix Prize)2000년, 넷플릭스가 퍼스널 라이즈 된 영화 추천을 도입하고 2006년에는 백만달러의 상금이 걸린 기계 학습 및 데이터 마이닝 대회인 넷플릭스상을 시작했습니다.당시 넷플릭스가 RMSE(root mean square error)가 0.9525의 자체 추천 시스템인 Cinematch를 사용하고 이 기준을 10%이상 넘도록 도전했습니다.목표를 달성하느냐, 1년 후에 목표에 다가간 팀은 상금이 주어집니다.1년 후의 2007년 진보상 수상자는 매트릭스 인수 분해(Matrix Factorization, 일명 SVD)에 한정된 볼츠만 기계(RBM)의 선형 조합을 사용하고 RMSE 0.88을 달성했습니다.넷플릭스가 소스 코드에 적응한 뒤 이들 알고리즘을 제작에 투입했습니다.주목할 점은 2009년에 일부 팀이 0.8567의 RMSE을 달성했음에도 불구하고 회사는 최소한의 정밀도 향상을 위해서 필요한 엔지니어링 노력으로 이들 알고리즘을 생산에 투입하지 않았다는 것입니다.이는 실제의 추천 시스템에서 중요한 점이다, 모델의 개선과 엔지니어링의 노력은 항상 긍정적인 관계가 있습니다.스트리밍- 새로운 소비 방식의 넷플릭스가 넷플릭스부터 개선된 모델을 통합하지 않은 보다 중요한 이유는 2007년에 스트리밍을 도입했기 때문이에요.스트리밍으로 데이터의 양이 급격히 증가했습니다.추천 시스템이 권장 사항을 생성하고 데이터를 수집할 방법을 바꿀 필요가 있습니다.
인기글





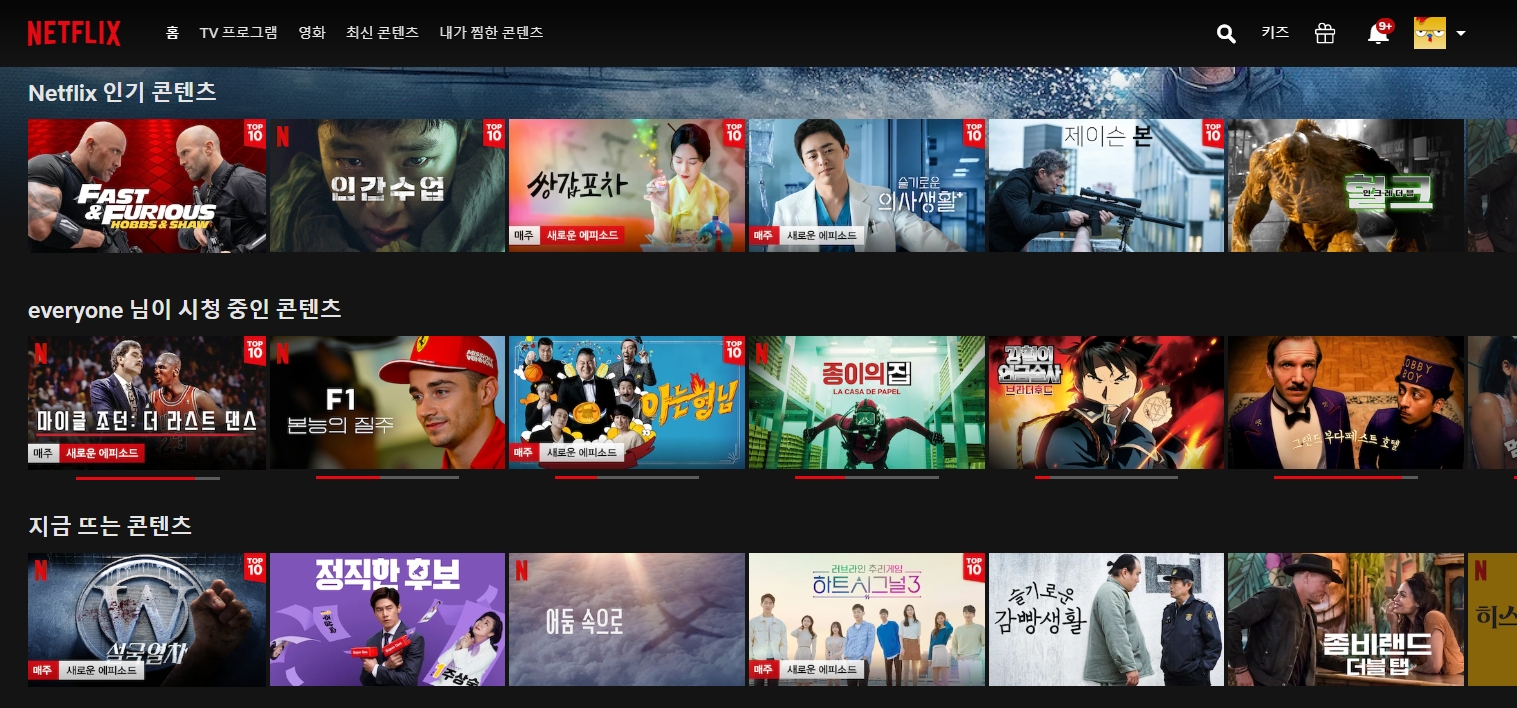
넷플릭스가 2020년 미국에서 DVD를 게시할 메일 서비스에서 1억 8,280만명의 가입자를 가진 글로벌 스트리밍 서비스로 변모했습니다.결과적으로 그 추천자 시스템은 등급을 예측하는 회귀 문제에서 순위 문제, 페이지 생성 문제, 사용자 경험을 최대화하는 문제(스트리밍 시간을 최대화하는 것, 즉 퍼스널 라이즈 할 수 있는 모든 것을 퍼스널 라이즈하는 것으로 정의된다)으로 변모했습니다.이 기사에서 다룰 주요 질문은 다음과 같습니다.넷플릭스가 어떤 추천 시스템을 사용하나요?비즈니스로서의 Netflix는 서브 스크립션 베이스 모델을 가지고 있습니다.한마디로, 넷플릭스의 회원 수가 많을수록 수익은 높아집니다.수익은 3개 기능으로 볼 수 있습니다.1. 신규 고객 획득율 2. 취소율 3)전의 멤버가 재가입하는 속도입니다.넷플릭스의 추천 시스템은 얼마나 중요합니까?스트리밍 시간의 80%는 넷플릭스의 추천 시스템을 통해서 달성되는데, 이는 매우 인상적인 수치입니다.또 Netflix는 보존율의 개선을 도모하는 사용자 경험을 낳고, 고객 확보 비용(2016년 시점에서 연간 약 1억달러)를 줄일 필요가 있다고 생각합니다.Netflix추천자 시스템 Netflix는 타이틀 순서를 어떻게 하나요?Netflix는 2단계 행 기반의 랭킹 시스템을 사용하고 있으며, 여기서 순위는 다음과 같습니다.1. 행 내에서(왼쪽에서 가장 강력한 권장 사항)2. 전행(가장 강력한 권장 사항)에 걸치고 있습니다.

들은 특정 주제(예:Top 10, Trending, Hor등)을 강조 표시하고 일반적으로 1개의 알고리즘을 사용하여 생성됩니다.각 회원의 홈페이지는 회원이 사용하는 기기에 의해서 최대 75항목으로 구성된 약 40줄로 구성되어 있습니다.왜 행일까요?장점은 두가지 관점에서 볼 수 있습니다.1)유사 항목의 행을 제시할 때 보다 일관성이 있고 그 범주에 속하는 항목을 시청하는 데 관심이 있는지를 결정할 수 있습니다.2)회사에서는 스크롤 다운을 하면서 줄 위에서 오른쪽으로 이동하는 것이 간단합니다.재미 있는 사실:여러분은 예술 작품이 당신의 프로필과 취향으로 퍼스널 라이즈 되는 것을 알고 있었나요?
어떤 알고리즘이 사용됩니까?넷플릭스가 각 모델의 아키텍처에 대해서 구체적인 내용은 명시되지 않지만 논문에서 언급된 다양한 랭커들을 사용합니다.다음은 이들 기능의 요약입니다. PVR(Personalized Video Ranking)이 알고리즘은 일반적으로 특정 기준(예:폭력적인 텔레비전 프로그램, 미국의 텔레비전 프로그램, 로맨스 등)로 카탈로그를 필터링 하는 범용 알고리즘에서 사용자 기능과 인기를 포함한 부가 기능과 결합됩니다.
PVR에 의해 생성된 항목의 예
상위 N개 비디오 순위 지정자(Top-N Video Ranker) PVR과 비슷하지만 순위 맨 위만 보고 전체 카탈로그를 봅니다. 카탈로그 순위(예: MAP@K, NDCG)의 헤드를 조사하는 메트릭을 사용하여 최적화됩니다.

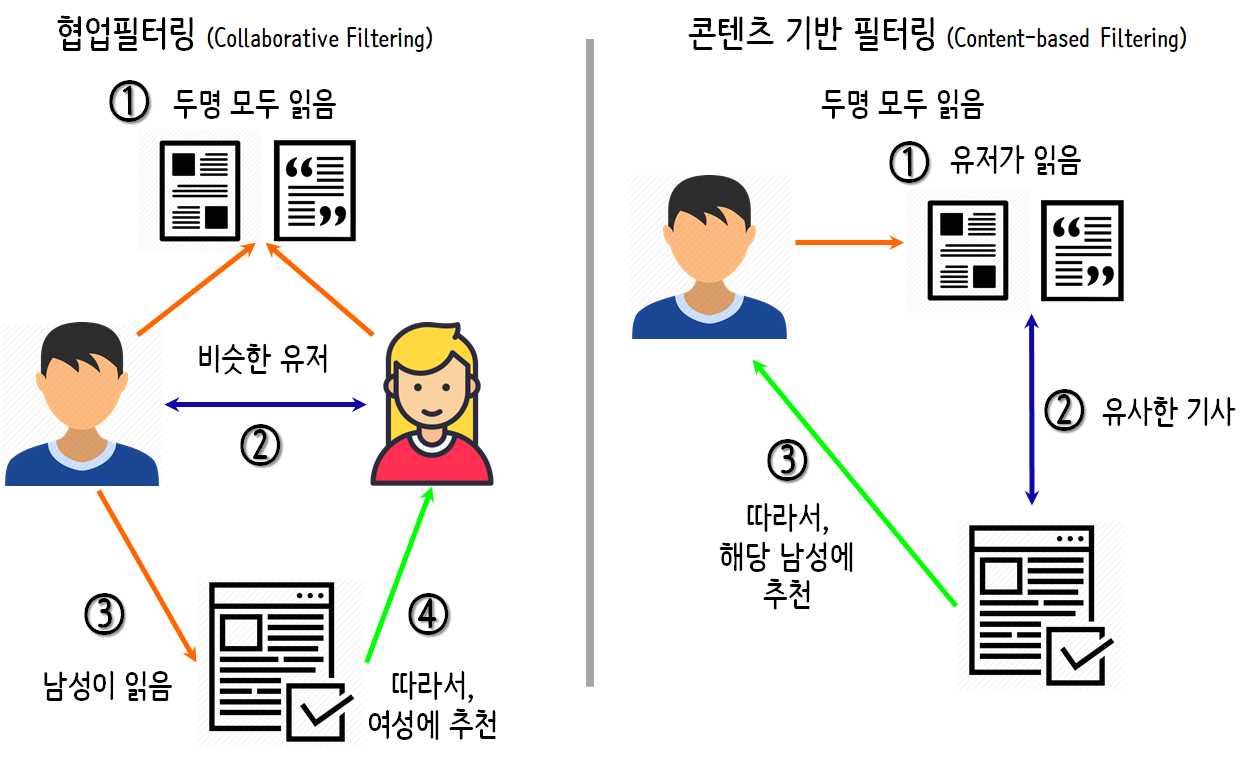
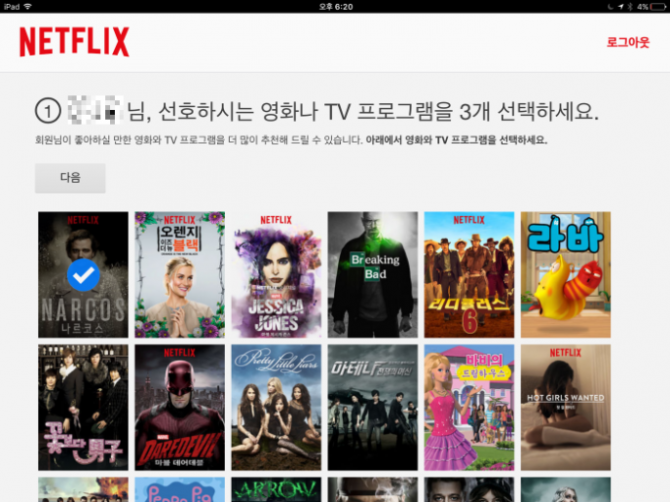
Top-N 랭커에서 생성된 제목의 예Trending Now Ranker이 알고리즘은 Netflix가 강력한 예측 변수로 추론할 시간적 경향을 파악합니다.이들의 단기적인 동향은 몇분부터 며칠까지 다양합니다.일반적으로 다음과 같은 이벤트/트렌드가 있습니다.1. 계절적인 경향이 있어 반복되는 이벤트(예를 들면, 발렌타인 데이는 소비되는 로맨스 비디오의 증가로 이어집니다)2.일회성 단기 사건(예:코로나 바이러스 또는 기타 재해에 의해서 해당 사건에 대한 다큐멘터리에 대한 단기적인 관심에 연결됩니다)Trending Now 랭커에서 생성된 제목의 예계속적인 랭커 감시(Continue Watching Ranker)이 알고리즘은 멤버가 사용했지만 완료하지 못한 항목을 다음과 같이 보고 갑니다.1. 일화 콘텐츠(예:드라마 시리즈)2. 사연이 아니라 컨텐츠에서 작은 피스로 소비할 수 있습니다(예:절반 완성한 영화 Black Mirror등의 에피소드에서 독립한 시리즈).알고리즘은 멤버가 감시하는 확률을 계산하고 다른 상황 인식 신호(예:시청 후 경과한 시간, 포기 시점, 감시 장치 등)을 포함합니다.랭커에서 생성된 제목을 계속 보기 예저스틴 바실리코의 프레젠테이션에서 그는 시간에 민감한 시퀀스 예측에 RN을 사용하는 것에 대해 발표했는데, 이 알고리즘에는 RN이 사용될 것이라고 생각합니다. 그는 넷플릭스가 상황 정보와 함께 특정 멤버의 과거 플레이를 사용하고, 이를 이용해 멤버들의 다음 플레이가 무엇인지 예측할 수 있도록 고안했습니다. 특히 연속 시간을 입력으로 이산 시간 컨텍스트와 함께 사용하는 것이 좋습니다.비디오-비디오 유사성 란카.(BYW Because you watched)이 알고리즘은 기본적으로 콘텐츠 기반의 필터링 알고리즘과 비슷합니다.멤버로 소비된 항목에 기초하여, 알고리즘은 다른 유사 항목을 계산하고 가장 유사한 항목을 갚겠습니다.다른 알고리즘에서 이 알고리즘은 다른 측면 기능이 사용되지 않았기 때문에 퍼스널 라이즈 되어 있지 않습니다.다만 특정 항목의 유사 항목을 회원 홈페이지( 자세한 내용은 아래 페이지 작성)에 표시하는 것은 의식적인 선택임에서 퍼스널 라이즈 됩니다.BYW에서 생성된 제목의 예행 생성 프로세스(Row Generation Process)상의 각 알고리즘은, 이하의 화상에 표시된 행 생성 프로세스를 거칩니다.예를 들어 PVR이 로맨스 타이틀을 보고 있는 경우, 이 장르에 맞는 후보자를 찾자 동시에 일행의 발표(예:멤버가 예전에 본 적이 있는 로맨스 영화)단서를 내놓게 됩니다.이 증거 선택 알고리즘은 위에 리스트 되고 있는 다른 모든 랭킹 알고리즘에 통합(또는 함께 사용되고 보다 체계적인 항목 리스트 랭킹을 작성하는 것을 알고 있습니다(이하 Netflix모델 워크 플로우 화상 참조).이 증거 선택 알고리즘은 “Netflix상단의 예상별 등급, 개요, 비디오와 관련 표시된 기타 사실(예를 들면, 수상, 캐스팅 또는 기타 메타 데이터)[Netflix]이[그들의]추천을 서포트하기 위해서 사용하는 화상 등, 페이지 왼쪽 위에 표시되어 있는 모든 정보를 사용합니다.행 및 UI의 다른 위치에 있습니다.”5개의 알고리즘은 각각 아래 그림과 같이 동일한 행 생성 프로세스를 거칩니다.페이지 생성 알고리즘이 후보 행을 생성한 후(이미 각 행 벡터 내에서 순위가 매겨진) 넷플릭스는 이 10,000 행 중에서 표시할 행을 어떻게 결정합니까?역사적으로 Netflix는 페이지 생성 문제, 즉 귀중한 화면 영역을 놓고 경쟁하는 수많은 미디어 경쟁 문제를 해결하기 위해서 템플릿 기반의 접근을 사용하고 왔습니다.정확성뿐만 아니라 다양성, 접근성, 안정성을 동시에 제공하는 데 초점을 맞춘 작업입니다.다른 고려 사항은 하드웨어 기능(사용 중인 디바이스)와 일견, 그리고 이동하는 때에 표시되는 행/열이 있습니다.넷플릭스가 해당 세션에서 이용자가 원하는 것을 정확히 예측했다가 빠진 영상을 받고 싶은지도 모른다는 점을 잊지 말자는 취지입니다.동시에 새로운 것을 제공하기로 카탈로그의 깊이를 강조하고 회원 지역에서 진행 중인 경향을 파악하고 싶습니다.마지막으로 멤버가 넷플릭스랑 잠시 교류하며 특정 방식으로 페이지를 탐색하는 데 익숙한 때 안정성이 필요합니다.이들 모든 요건으로 템플릿 기반의 접근이 항상 충족되지 않으면 안 되는 몇가지 고정된 기준 세트를 가질 수 있어 처음부터 아주 잘 기능할 이유가 나타납니다.그러나 그런 많은 규칙이 시행되고 자연스럽게 넷플릭스가 좋은 회원 경험을 제공한다는 측면에서 지역 최적지에 도달했어요.그럼 이 행의 순위 문제에 어떻게 접근해야 할까요?행 기반의 접근행 기반의 접근법이 기존의 권장 사항 또는 순위 부여 방법을 사용하고들에게 점수를 매기는 그 점수로 순위를 붙입니다.이 접근은 비교적 빠를지도 모르지만, 다양성이 떨어지고 있습니다.멤버는 통상 자신의 관심사와 일치할 행이 가득한 페이지를 보는데, 행 단위도 매우 닮은 경우가 있습니다.그럼 우리는 다양성을 어떻게 통합해야 할까요?단계적 접근들이 상기의 방법처럼 점수를 매기는 단계적 접근 방식을 사용할, 행 상승 접근 개선입니다.다만, 행은 첫줄부터 순차적으로 선택되어 행을 선택할 때마다 페이지에 대하여 이미 선택되는 앞의 항목과 앞줄의 양쪽과의 관계를 고려하고 다음 행이 재계산됩니다.이것은 단순한 욕심의 단계적 접근 방식입니다.들에 대한 점수를 계산할 때 다음 k행을 고려한 k-row예상 접근법을 사용하면 이 문제를 개선할 수 있습니다.그러나 이들의 접근 모두 글로벌 최적화를 달성할 수 없습니다.머신 러닝 어프로치 넷플릭스가 사용하는 해법과 접근법은 머신 러닝(Machine Learning)에서 실제로 본 내용, 상호 작용한 방법, 플레이한 내용 등 회원을 위해서 만든 홈페이지의 역사적 정보를 사용하여 모델을 교육하는 것을 목표로 하고 있습니다.물론 이 알고리즘은 홈페이지에서 특정 행을 나타낼 수 있는 많은 기능과 방법이 있습니다.항목 메타 데이터를 모두 내장하고 집계하거나 위치별로 색인을 붙이는 것만큼이나 간단합니다.페이지를 나타내는데 어떤 기능이 사용되고도 주요 목표는 가상의 페이지를 작성하는 사용자가 어느 항목과 상호 작용했는지를 확인하는 것입니다.다음에 Precision@m-by-n및 Recall@m-by-n 같은 페이지 수준 메트릭을 사용하여 점수를 매깁니다(Precision@k및 Recall@k의 적응지만 2차원 공간에 있다).콜드 스타트(Cold-Start)구축 및 빅 데이터 콜드 스타트 문제, 낡은 콜드 스타트 문제는 넷플릭스도 가지고 있습니다.전통적으로, 넷플릭스가 새로운 회원으로 추천을 “점프 스타트” 하기 위한 설문 조사를 작성하도록 요청함으로써 일부 사용자 선호도 정보를 얻음으로써 이를 억제하려고 노력합니다.이 단계를 스킵 할 경우 권장 사항 엔진은 다양하고 인기가 있는 제목세트를 제공합니다.또 최근 이 신종 코로나 바이러스의 기간에 Netflix Party(Chrome확장 기능)이 만들어졌고 이들 데이터는 분석 때문에 Netflix에 재전송되기 때문에 이런 콜드 스타트 문제를 억제하는 데 큰 영향을 준다고 생각하고 있습니다.간단히 말하면, 넷플릭스가 한 활동(적어도 넷플릭스가 감시할 수 있는 것이었습니다.집에서 혼자 볼 수 있지만, 넷플릭스가 당신이 누구와 물리적으로 보고 있는지 전혀 모릅니다.Netflix Party로 Netflix는 잠재적으로 사용자와 상호 작용한 사람의 그래프를 작성할 수 있어 새로운 사용자에게도 권장되는 알고리즘 같은 협업 필터링을 실시할 수 있습니다.모두 A/Bout테스트 오프라인 평가와 온라인 평가의 격차는 여전히 남아 있습니다.오프라인 메트릭은 모델이 훈련 데이터에 대해서 얼마나 잘 실행되는지를 평가하는 데 도움이 되는데, 이러한 결과가 실제 사용자 경험(즉 총 감시 시간)의 개선으로 이어진다는 보장은 없습니다.이처럼 인터넷 플릭 스팀은 자신들이 구축한 이들 새로운 알고리즘을 신속하게 테스트하기 위해서 놀라운 효율적인 A/B시험 프로세스를 실시하고 있습니다.제어 및 시험 그룹을 선택하는 방법, A/B시험이 통계적으로 중요한지(예:전체 사용자 환경 개선), 제어/테스트 그룹의 크기 선택, A/B시험에 사용하는 메트릭 등 고려해야 할 변수가 많아 A/B시험 자체는 기술입니다.기본적으로 오프라인 평가는 넷플릭스가 A/B시험에 모델을 투입할 시기와 A/B시험에 사용하는 모델을 결정하는데 도움이 됩니다.데이터, 데이터, 데이터 및 기타 데이터 온라인 스트리밍을 통해서 Netflix가 관리 및 접근 할 수 있는 데이터는 무한합니다.이들 양의 데이터를 관리하는 것은 오프라인, 온라인 및 니어 라인 컴퓨팅을 분리하는 바른 아키텍처에서만 가능합니다.오프라인 계산에서는 알고리즘이 완화된 타이밍 요건과 함께 일괄 실행되므로 데이터 양과 계산의 복잡함에 대한 제한은 적게 됩니다.다만, 최신 데이터가 통합되지 않아 기록 중에 예전 데이터가 될 가능성이 있습니다.퍼스널 라이즈 된 아키텍처에서는 온라인과 오프라인의 컴퓨팅을 심리스에 조합이 중요한 문제입니다.온라인 연산을 통해서 우리는 최근의 사건과 사용자의 상호 작용에 대한 응답을 기대하고 싶어 실시간으로 그렇지 않으면 안 됩니다.그래서 온라인 연산은 복잡해서 계산 비용이 안 들어요.또 사전 계산된 결과화 같은 대체 메커니즘이 필요합니다.니어 라인 계산을 통해서 온라인과 유사한 계산을 할 수 있지만 실시간으로 제공할 필요는 없는 동기적으로 사용할 수 있다는 점에서 2가지 접근법 간의 중간 타협점을 얻을 수 있습니다.이는 회원이 영화를 관람하기 시작한 뒤 곧바로 영화를 관람한 것을 반영하기 위해서 추천 사항을 업데이트하는 등 이벤트별로 복잡한 처리가 이루어지는 문을 엽니다.이는 증분 학습 알고리즘에 도움이 됩니다.다음은 넷플릭스의 상세한 아키텍처 그림입니다.원본 출처 : towardsdatascience.com “Deep Dive into Netflix’s Recommender System” 상의 아티클은 아래 카뷰에서도 확인할 수 있습니다.http://pf.kakao.com/_xgzxlubBB7942쉼터_함께 자랍니다.생활에 도움이 되는 자료가 축척되어 있는 공간 pf.kakao.com* 카뷰친구추천하신분 댓글에 친구추천번호와 링크 남겨주시면 맞추겠습니다.